Streaming Platform
Arquitectura General
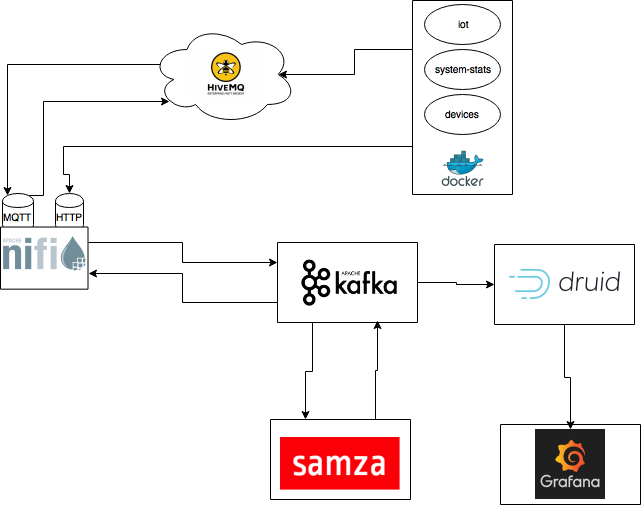
En el diagrama podemos ver la arquitectura del sistema que vamos a implementar, su funcionamiento es el siguiente:
- Los datos son envios desde 3 sensores que emularemos en docker. Estos datos son enviados mediante MQTT a una broker en la cloud HiveMQ y mediante peticiones POST HTTP.
- Nifi se encarga de consumir los mensajes desde el broker MQTT en la cloud y de atender las peticiones POST HTTP de los sensores, ambas fuentes son procesadas y enviadas a distintos topics de Kafka. Nifi también envía los mensajes de control generados por el motor de streaming, que serán enviados de nuevo al broker en la cloud.
- Samza, que se ejecutará sobre Hadoop YARN, es el encargado de leer los mensajes de los sensores desde Kafka y procesarlos, en base a este procesamiento se generarán mensajes de métricas y mensajes de control.
- Druid leerá los mensajes de métricas generados por Samza y los indexará.
- Finalmente, veremos los datos almacenados en Druid utilizando una interfaz de visualización que es Grafana.
Nifi Template
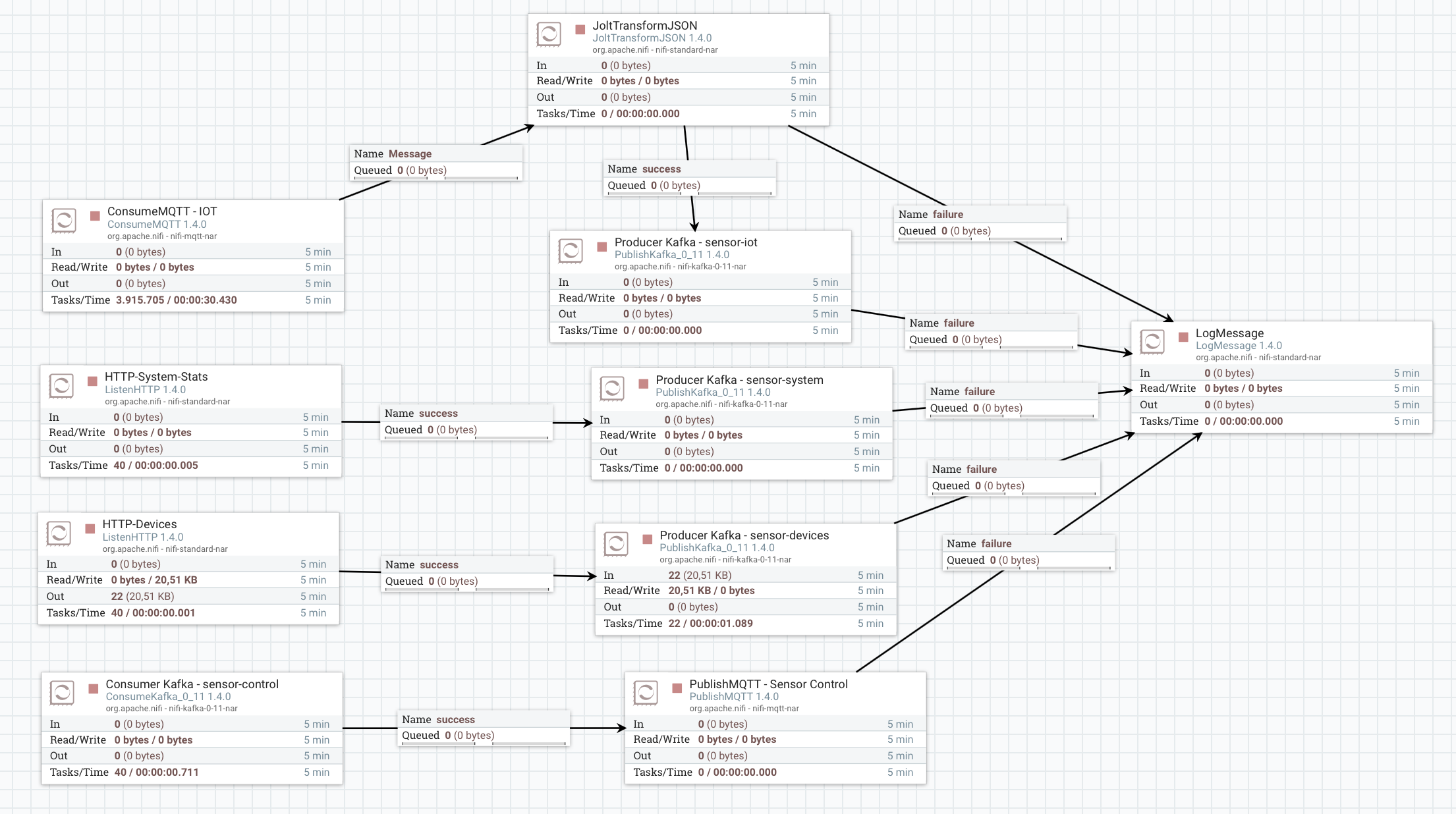
Download: Nifi Template
El template de Nifi es el encargado de:
- Escuchar las peticiones POST desde los sensores y enviarlas a los correspondientes topics de Kafka.
- Consumir los mensajes del broker MQTT, transformar los JSONs y enviarlos a Kafka.
- Consumir desde Kafka los mensajes de control y enviarlos al broker MQTT.
Kafka Topics
En esta sección vamos a analizar los topics de usuario que vamos a utilizar en nuestro sistema.
- sensor-control : Es utilizado para enviar ordenes de control a los sensores.
- sensor-iot : Es utilizado para recibir los datos de el sensor de iot.
- sensor-system : Es utilizado para enviar los datos del sensor de métricas de sistema.
- sensor-devices : Es utilizado para enviar los datos del sensor de dispositivos.
- sensor-system-metrics : Es utilizado para enviar las métricas del sistema procesadas por Samza.
- sensor-data-metrics : Es utilizado para enviar las métricas de tiempo y dispositivos desde Samza.
Instalación
Zookeeper y kafka
Para instalar ZooKeeper y Kafka podemos seguir la guía que tenemos en esta misma web. Instalación Zookeeper y Kafka
Nifi
Instalación
En primer lugar tenemos que descargar la distribución, podemos encontrar la última distribución en Nifi Downloads. Actualmente es la versión 1.4.0.
wget http://apache.rediris.es/nifi/1.4.0/nifi-1.4.0-bin.tar.gz
Una vez la tenemos la descomprimimos y ya podemos ejecutarlo:
tar -xvf nifi-1.4.0-bin.tar.gz; cd nifi-1.4.0/
# Ejeccución en primer plano
bin/nifi.sh run
# Ejeccución en segundo plano
bin/nifi.sh start
Una vez el sistema este operativo podemos acceder a la URL: http://localhost:8080/nifi
Ejeccución del template
Download: Nifi Template
Al acceder a la URL http://localhost:8080/nifi, encontraremos una interfaz como la siguiente:
Una vez vemos la interfaz podemos cargar nuestro template de la siguiente forma, seleccionamos nuestro template y lo cargamos:
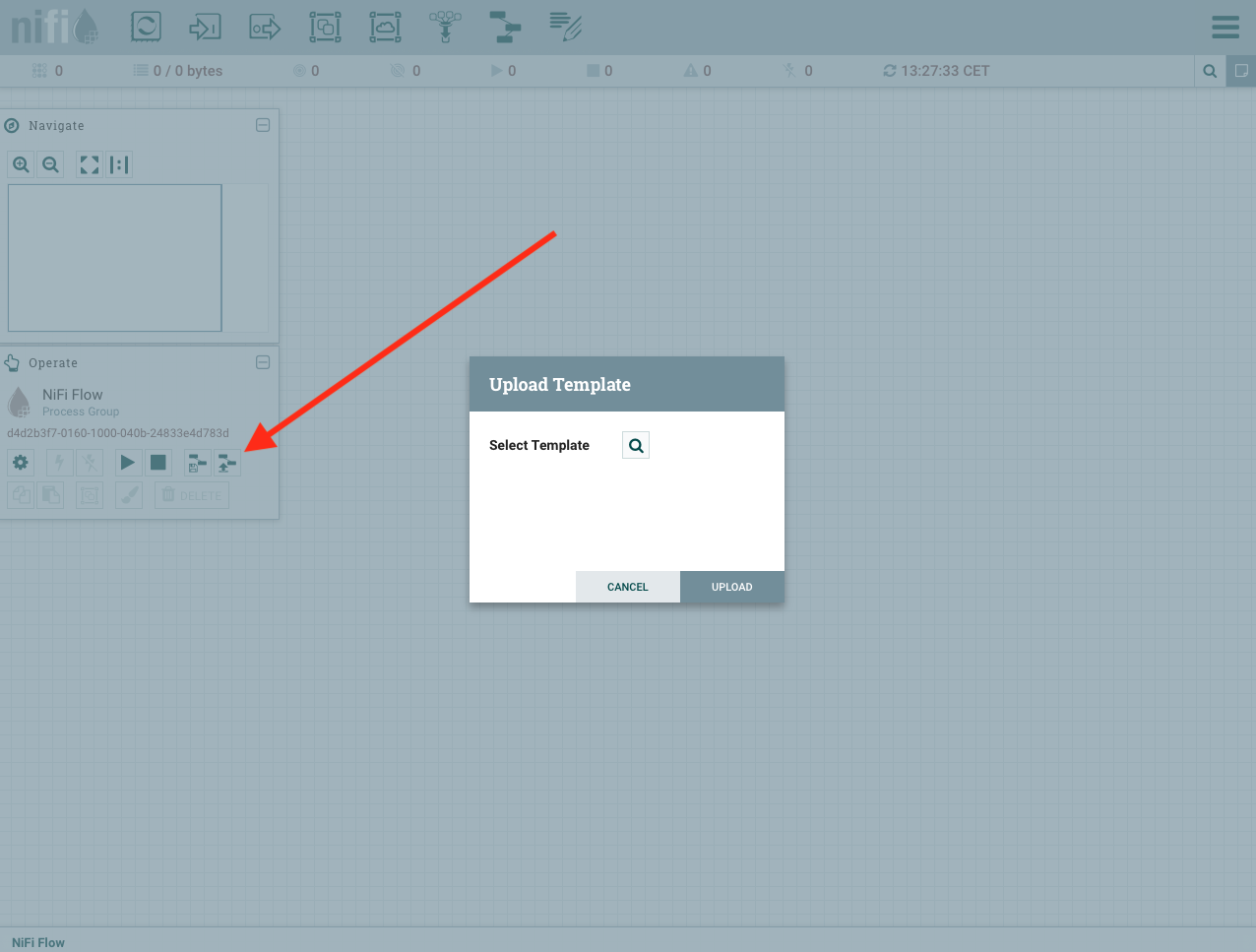
Ahora toca agregar nuestro template al flow de Nifi, hacemos un drag&drop de un template y seleccinamos el template que hemos cargado:
Una vez tenemos el template cargado, ya podemos ejecutarlo:
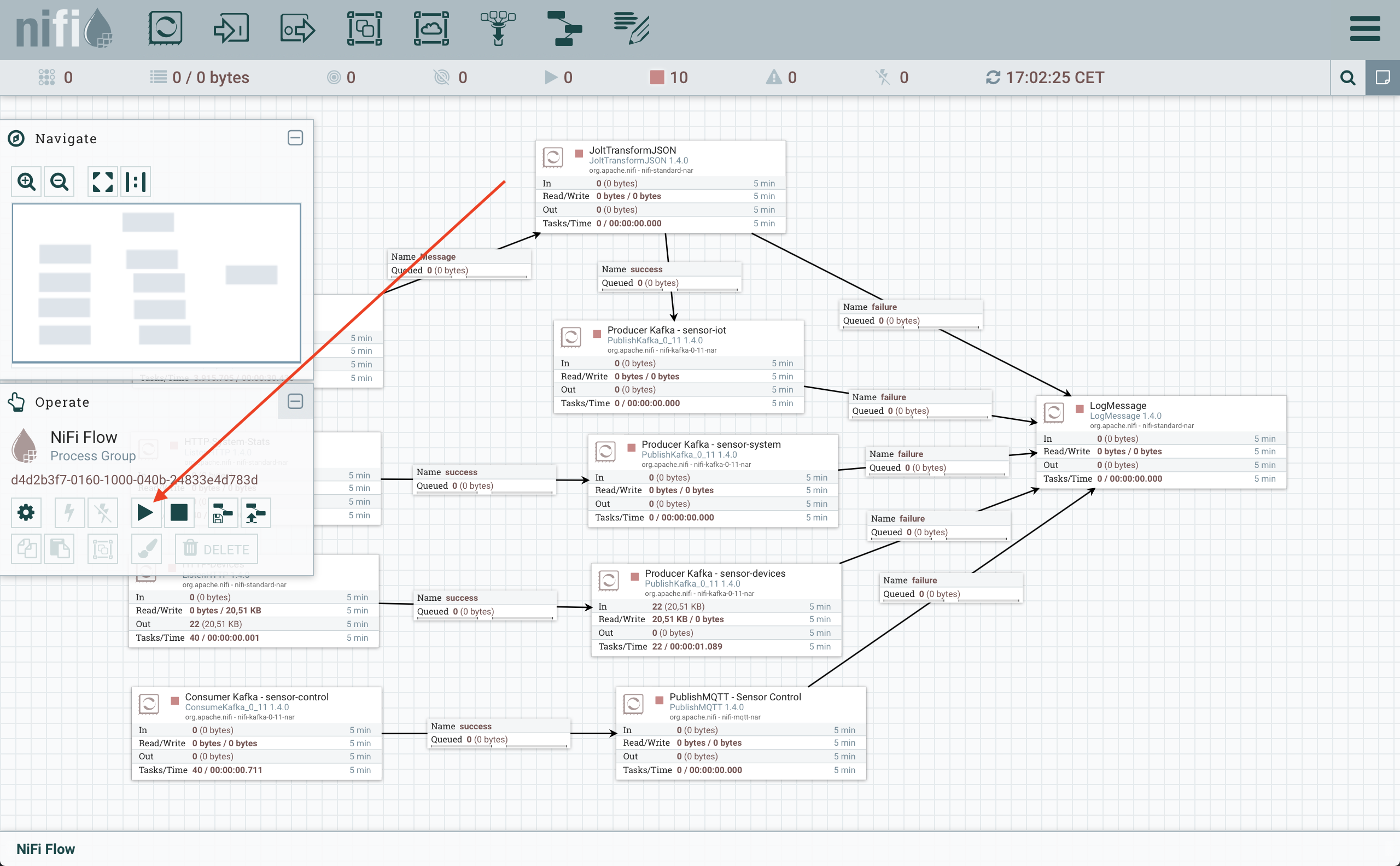
Cuando hayamos finalizado este procedimiento ya tendremos ejecutando nuestro template de Nifi, que se encargara de procesar los mensajes.
Sensores
Los sensores se pueden encontrar en el github del proyecto, el como construir los docker y ejecutarlos se encuentran en los README.md de cada uno de ellos.
Hadoop YARN
Para instalar Hadoop podemos seguir la guía que tenemos en esta misma web. Instalación Hadoop YARN
Samza
El código de Samza lo podemos encontrar en el repo del proyecto: Samza Task Source Code
Para compilar el proyecto usaremos maven
mvn clean package
Esto generará un tar.gz que al descrompirlo obtendremos las utilidades necesarias, para ejecutar la APP de samza.
bin/run-job.sh --config-path src/config/stream-samza.properties
Notas:
- Tener ejecutando Zookeeper y Kafka
- Tener ejecutando Hadoop YARN
- El directorio
/var/log/samza/debe existir.
Druid
Para instalar Druid podemos seguir la guía que tenemos en esta misma web. Instalación Hadoop YARN
- Sensor System Druid Supervisor Spec
{
"type": "kafka",
"dataSchema": {
"dataSource": "sensor-system-metrics",
"parser": {
"type": "string",
"parseSpec": {
"format": "json",
"timestampSpec": {
"column": "timestamp",
"format": "ruby"
},
"dimensionsSpec": {
"dimensions": [],
"dimensionExclusions": [
"timestamp",
"value"
]
}
}
},
"metricsSpec": [
{
"name": "count",
"type": "count"
},
{
"name": "value_sum",
"fieldName": "value",
"type": "doubleSum"
},
{
"name": "value_min",
"fieldName": "value",
"type": "doubleMin"
},
{
"name": "value_max",
"fieldName": "value",
"type": "doubleMax"
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "MINUTE"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsPerSegment": 5000000
},
"ioConfig": {
"topic": "sensor-system-metrics",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
},
"taskCount": 1,
"replicas": 1,
"taskDuration": "PT1H"
}
}
- Sensor Data Druid Supervisor Spec
{
"type": "kafka",
"dataSchema": {
"dataSource": "sensor-data-metrics",
"parser": {
"type": "string",
"parseSpec": {
"format": "json",
"timestampSpec": {
"column": "timestamp",
"format": "ruby"
},
"dimensionsSpec": {
"dimensions": ["sensor"]
}
}
},
"metricsSpec": [
{
"name": "count",
"type": "count"
},
{
"name": "rssi_sum",
"fieldName": "rssi",
"type": "doubleSum"
},
{
"name": "temperature_sum",
"fieldName": "temperature",
"type": "doubleSum"
},
{
"name": "temperature_min",
"fieldName": "temperature",
"type": "doubleMin"
},
{
"name": "temperature_max",
"fieldName": "temperature",
"type": "doubleMax"
},
{
"name": "humidity_sum",
"fieldName": "humidity",
"type": "doubleSum"
},
{
"name": "humidity_min",
"fieldName": "humidity",
"type": "doubleMin"
},
{
"name": "humidity_max",
"fieldName": "humidity",
"type": "doubleMax"
},
{
"name": "clients",
"fieldName": "device",
"type": "hyperUnique"
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "MINUTE"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsPerSegment": 5000000
},
"ioConfig": {
"topic": "sensor-data-metrics",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
},
"taskCount": 1,
"replicas": 1,
"taskDuration": "PT1H"
}
}
Para ejecutar las tareas de indexación debemos subir los ficheros mediante dos peticiones POST al Overlord.
curl -X POST -H 'Content-Type: application/json' -d @kafka-index.json http://localhost:8090/druid/indexer/v1/supervisor
Grafana
La instalación de grafana es tan simple como seguir el proceso de su web dependiendo de la distribución que usemos Grafana Download
Una vez tengamos instalado grafana, debemos añadir el plugin que da el soporte para Druid, que es tan sencillo como ejecutar la siguiente linea:
git clone https://github.com/grafana-druid-plugin/druidplugin.git /usr/local/var/lib/grafana/plugins/druidplugin
Nota: La ruta /usr/local/var/lib/grafana/plugins/druidplugin es por defecto, puede variar dependiendo del sistema, hay que utilizar el directorio donde grafana almacena los plugins.