Spark
Spark Standalone Cluster Deployment
Para comenzar vamos a descargar y descomprimir la distribución de spark:
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz; tar -xvf spark-2.2.0-bin-hadoop2.7.tgz; cd spark-2.2.0-bin-hadoop2.7
Spark Master & Spark UI
En primer lugar vamos a ejecutar el nodo master:
./sbin/start-master.sh
Cuando lo tengamos veremos una salida de log como la siguiente:
17/10/19 12:06:43 INFO Utils: Successfully started service 'sparkMaster' on port 7077.
17/10/19 12:06:43 INFO Master: Starting Spark master at spark://andresgomezfrr.local:7077
17/10/19 12:06:43 INFO Master: Running Spark version 2.2.0
17/10/19 12:06:44 INFO Utils: Successfully started service 'MasterUI' on port 8080.
17/10/19 12:06:44 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://192.168.1.106:8080
17/10/19 12:06:44 INFO Utils: Successfully started service on port 6066.
17/10/19 12:06:44 INFO StandaloneRestServer: Started REST server for submitting applications on port 6066
17/10/19 12:06:44 INFO Master: I have been elected leader! New state: ALIVE
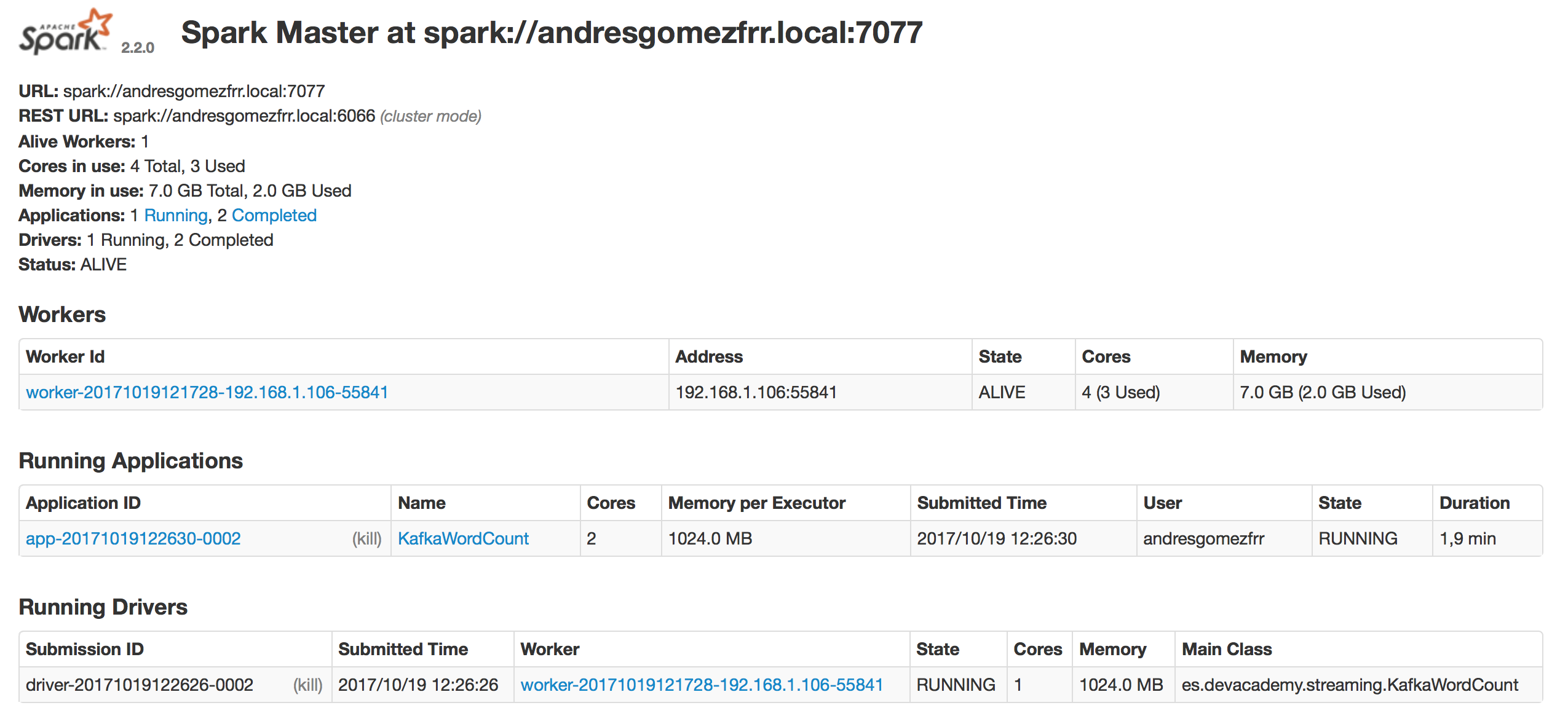
Y podremos acceder a la Spark UI: http://192.168.1.106:8080
Spark Workers
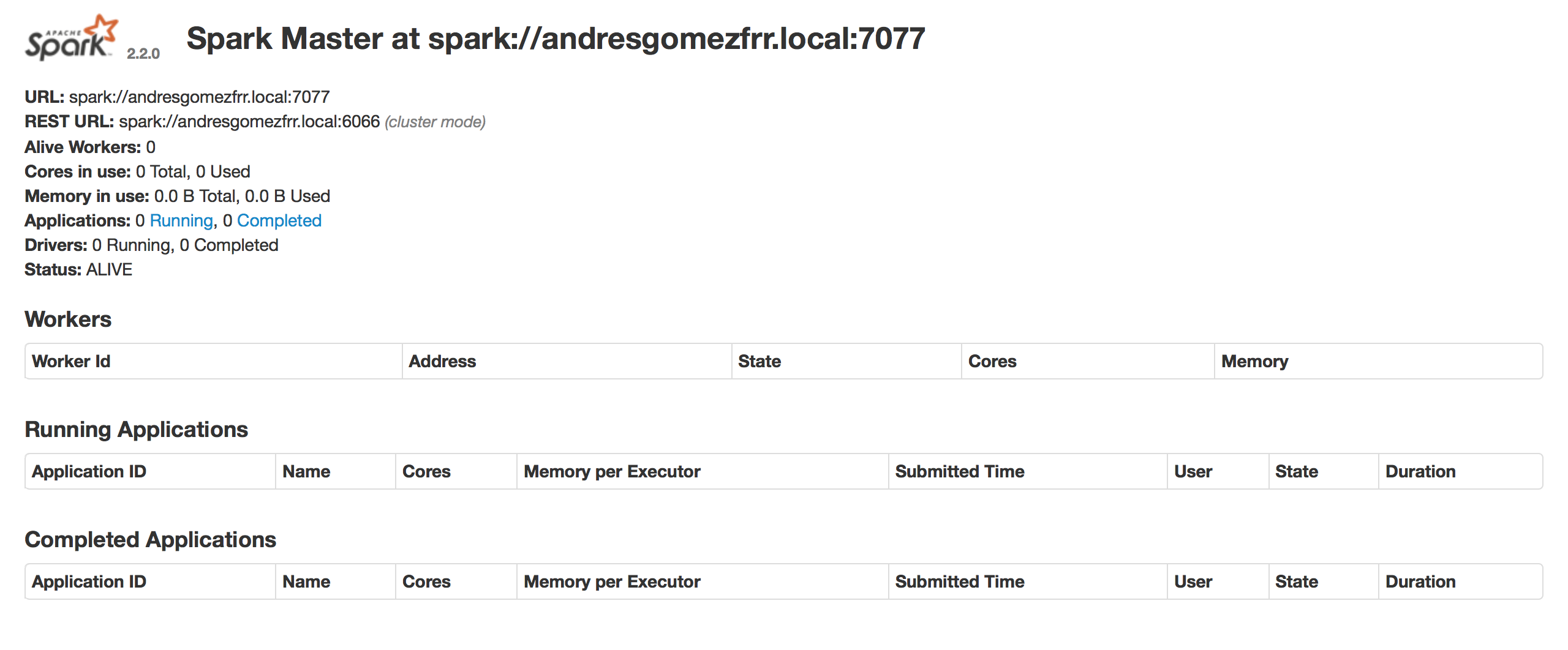
Ahora vamos a ejecutar los workers, que son los que añaden recursos al cluster:
./sbin/start-slave.sh <master-spark-URL>
Tenemos que indicar la URL del master, en mi caso: spark://andresgomezfrr.local:7077. Si ahora volvemos a visitar la web de Spark, veremos que tenemos registrado un worker.
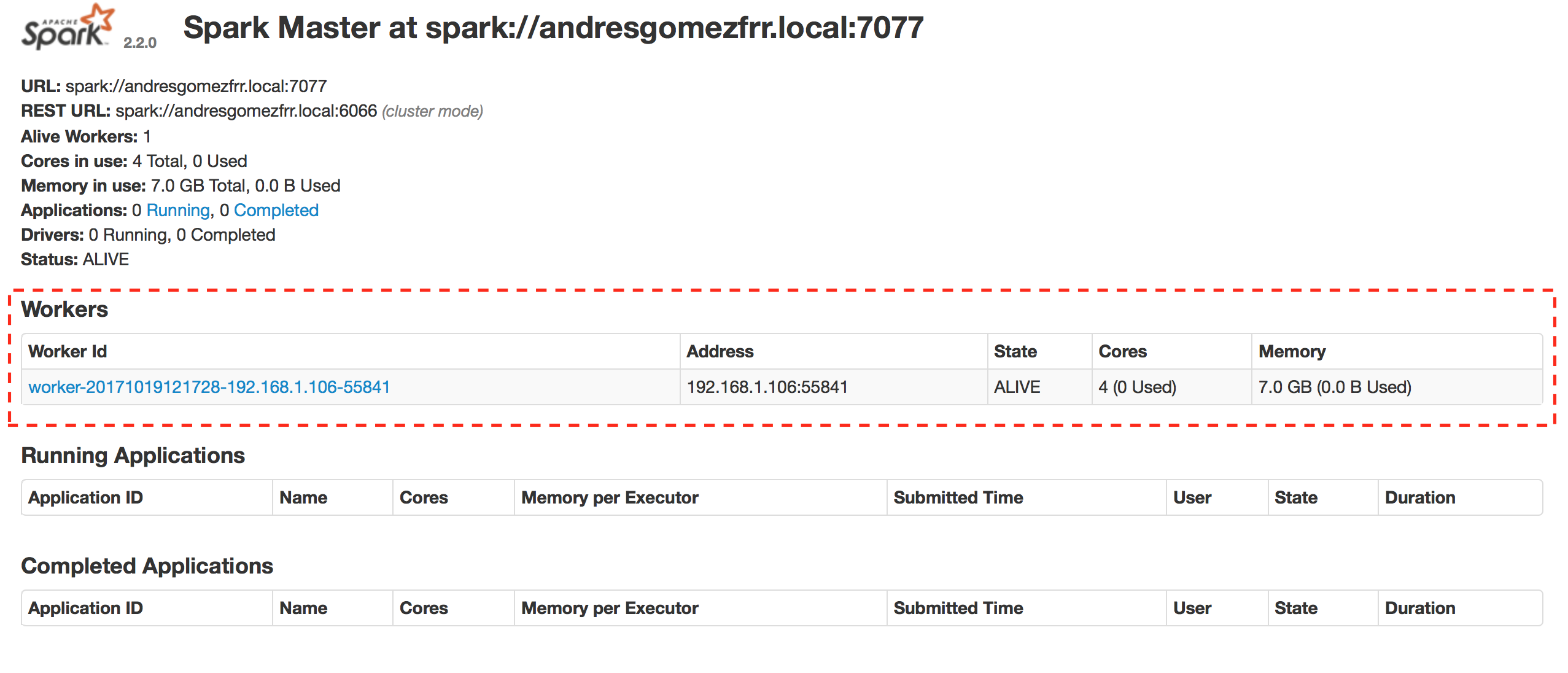
Example App
Ya que tenemos nuestro cluster operativo podemos probar a ejecutar una aplicación usando el comando spark-submit
./bin/spark-submit --master spark://192.168.1.106:7077 \
--executor-cores 1 --executor-memory 1G \
--deploy-mode cluster --executor-cores 2 \
--class streaming.KafkaWordCount \
--total-executor-cores 4 --supervise sample-spark.jar
Y podemos ver que esta operativa en la Spark UI.